17. 强化学习¶
Pratik Chaudhari (宾夕法尼亚大学和亚马逊), Rasool Fakoor (亚马逊), 和 Kavosh Asadi (亚马逊)
强化学习(Reinforcement Learning,RL)是一套让我们能够构建按顺序做决策的机器学习系统的一系列技术。例如,你从在线零售商那里购买的新衣服的包裹,是在一系列决策之后才送到你家门口的,例如,零售商在你家附近的仓库中找到衣服,将衣服放入箱子,通过陆运或空运运输箱子,并在城市内将它送到你家。在此过程中,有很多变量会影响包裹的递送,例如,仓库里是否有衣服,运输箱子花了多长时间,它是否在每日派送卡车离开前到达你所在的城市,等等。关键思想是,在每个阶段,这些我们通常无法控制的变量会影响未来的整个事件序列,例如,如果仓库包装箱子时出现延误,零售商可能需要通过空运而不是陆运来发送包裹,以确保及时送达。强化学习方法让我们能够在顺序决策问题的每个阶段采取适当的行动,以便最终最大化某些效用,例如,及时将包裹送到你手中。
这类顺序决策问题在许多其他地方也能见到,例如,下围棋时,你当前的走法决定了接下来的走法,而对手的走法是你无法控制的变量……一系列的走法最终决定了你是否能赢;Netflix现在向你推荐的电影决定了你看什么,Netflix并不知道你是否喜欢这部电影,最终一系列的电影推荐决定了你对Netflix的满意度。如今,强化学习正被用于为这些问题开发有效的解决方案 (Mnih et al., 2013, Silver et al., 2016)。强化学习和标准深度学习之间的关键区别在于,在标准深度学习中,训练好的模型对一个测试数据的预测不会影响对未来测试数据的预测;而在强化学习中,未来的决策(在强化学习中,决策也称为动作)会受到过去所做决策的影响。
在本章中,我们将阐述强化学习的基础知识,并亲手实践实现一些流行的强化学习方法。我们首先将建立一个名为马尔可夫决策过程(Markov Decision Process, MDP)的概念,它让我们能够思考这类顺序决策问题。一种名为价值迭代(Value Iteration)的算法将是我们解决强化学习问题的第一个见解,前提是我们知道MDP中不受控制的变量(在强化学习中,这些受控制的变量被称为环境)通常如何表现。使用更通用的价值迭代版本——Q学习(Q-Learning)算法,即使我们不完全了解环境,也能够采取适当的行动。然后,我们将研究如何通过模仿专家的行动来将深度网络用于强化学习问题。最后,我们将开发一种使用深度网络在未知环境中采取行动的强化学习方法。这些技术构成了更高级强化学习算法的基础,这些算法如今已在各种现实世界的应用中使用,我们将在本章中指出其中一些应用。
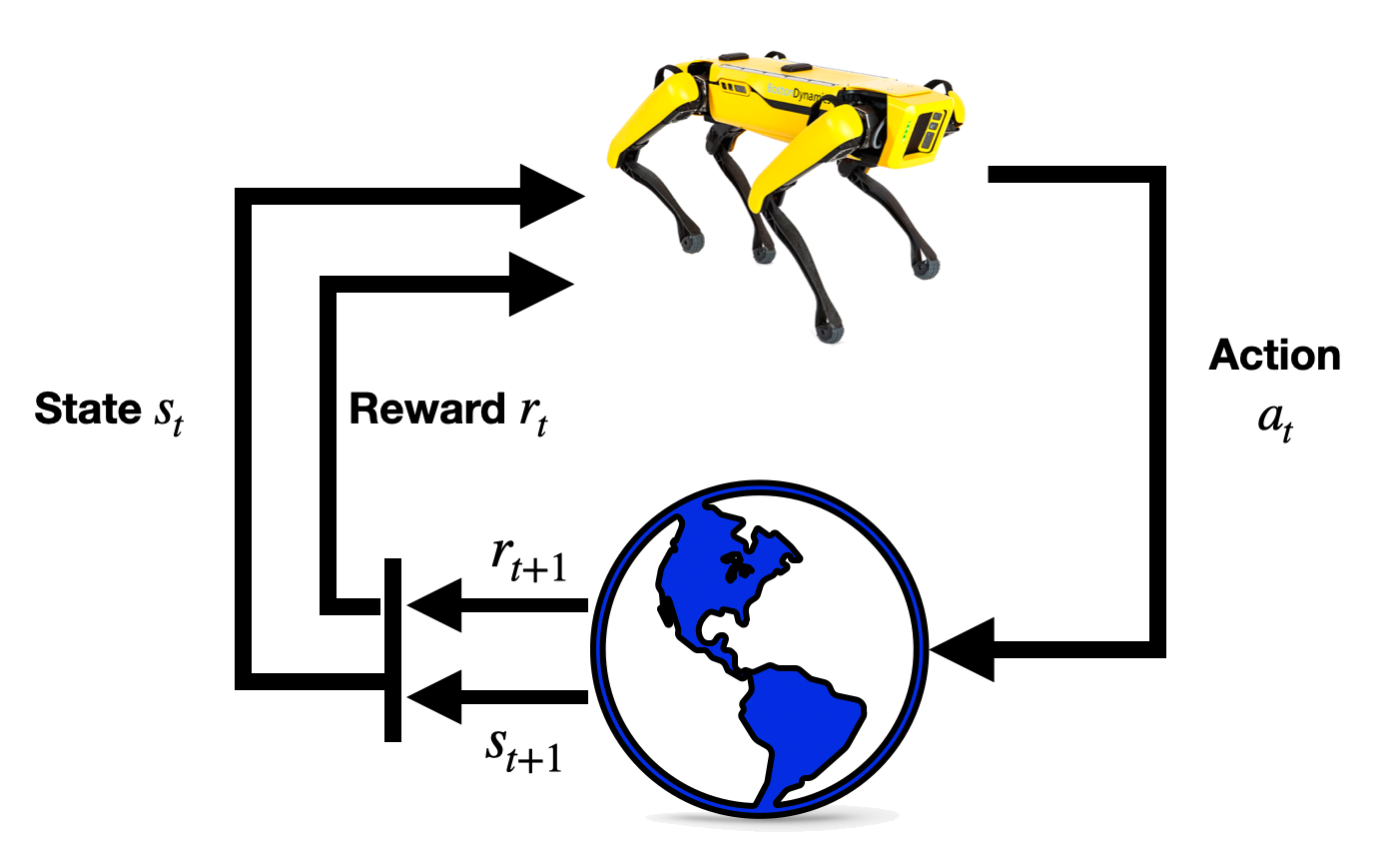
图 17.1 强化学习结构¶