21.2. MovieLens数据集¶ 在 SageMaker Studio Lab 中打开 Notebook
有许多可用于推荐研究的数据集。其中,MovieLens 数据集可能是最受欢迎的数据集之一。MovieLens是一个非商业的、基于Web的电影推荐系统。它创建于1997年,由明尼苏达大学的一个研究实验室GroupLens运营,旨在为研究目的收集电影评分数据。MovieLens数据对个性化推荐和社会心理学等多项研究至关重要。
21.2.1. 获取数据¶
MovieLens数据集由GroupLens网站托管。有几个版本可用。我们将使用MovieLens 100K数据集 (Herlocker et al., 1999)。该数据集包含来自943位用户对1682部电影的\(100,000\)条评分,评分范围从1星到5星。该数据集已经过清理,确保每个用户至少对20部电影进行了评分。还提供了一些简单的用户和项目的人口统计信息,例如年龄、性别、类型。我们可以下载ml-100k.zip并解压出u.data文件,该文件以csv格式包含了所有\(100,000\)条评分。文件夹中还有许多其他文件,每个文件的详细描述可以在数据集的README文件中找到。
首先,我们导入运行本节实验所需的包。
import os
import pandas as pd
from mxnet import gluon, np
from d2l import mxnet as d2l
然后,我们下载MovieLens 100k数据集,并将交互数据加载为DataFrame。
#@save
d2l.DATA_HUB['ml-100k'] = (
'https://files.grouplens.org/datasets/movielens/ml-100k.zip',
'cd4dcac4241c8a4ad7badc7ca635da8a69dddb83')
#@save
def read_data_ml100k():
data_dir = d2l.download_extract('ml-100k')
names = ['user_id', 'item_id', 'rating', 'timestamp']
data = pd.read_csv(os.path.join(data_dir, 'u.data'), sep='\t',
names=names, engine='python')
num_users = data.user_id.unique().shape[0]
num_items = data.item_id.unique().shape[0]
return data, num_users, num_items
21.2.2. 数据集统计¶
让我们加载数据并手动检查前五条记录。这是了解数据结构并验证数据是否已正确加载的有效方法。
data, num_users, num_items = read_data_ml100k()
sparsity = 1 - len(data) / (num_users * num_items)
print(f'number of users: {num_users}, number of items: {num_items}')
print(f'matrix sparsity: {sparsity:f}')
print(data.head(5))
number of users: 943, number of items: 1682
matrix sparsity: 0.936953
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
我们可以看到,每行由四列组成,包括“用户ID”(1-943)、“项目ID”(1-1682)、“评分”(1-5)和“时间戳”。我们可以构建一个大小为\(n \times m\)的交互矩阵,其中\(n\)和\(m\)分别是用户数和项目数。该数据集仅记录了已有的评分,所以我们也可以称之为评分矩阵,在矩阵值代表确切评分的情况下,我们将交替使用交互矩阵和评分矩阵。评分矩阵中的大多数值是未知的,因为用户没有对大多数电影进行评分。我们还显示了该数据集的稀疏度。稀疏度定义为1 - 非零条目数 / ( 用户数 * 项目数)。显然,交互矩阵是极其稀疏的(即稀疏度=93.695%)。现实世界的数据集可能遭受更严重的稀疏性问题,这一直是构建推荐系统中的一个长期挑战。一个可行的解决方案是使用额外的辅助信息,如用户/项目特征,来缓解稀疏性问题。
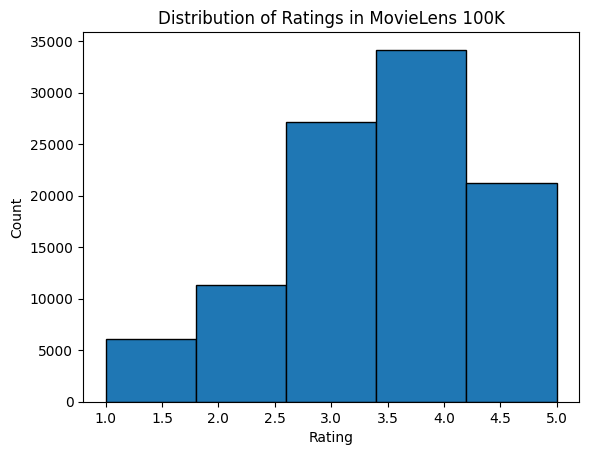
然后我们绘制不同评分计数的分布图。正如预期的那样,它呈现出正态分布,大部分评分集中在3-4分。
d2l.plt.hist(data['rating'], bins=5, ec='black')
d2l.plt.xlabel('Rating')
d2l.plt.ylabel('Count')
d2l.plt.title('Distribution of Ratings in MovieLens 100K')
d2l.plt.show()
21.2.3. 划分数据集¶
我们将数据集划分为训练集和测试集。以下函数提供两种划分模式,包括random和seq-aware。在random模式下,函数会随机划分10万条交互数据,不考虑时间戳,默认使用90%的数据作为训练样本,其余10%作为测试样本。在seq-aware模式下,我们将用户最近评分的项目作为测试集,将用户的历史交互作为训练集。用户的历史交互根据时间戳从旧到新排序。此模式将在序列感知推荐部分使用。
#@save
def split_data_ml100k(data, num_users, num_items,
split_mode='random', test_ratio=0.1):
"""Split the dataset in random mode or seq-aware mode."""
if split_mode == 'seq-aware':
train_items, test_items, train_list = {}, {}, []
for line in data.itertuples():
u, i, rating, time = line[1], line[2], line[3], line[4]
train_items.setdefault(u, []).append((u, i, rating, time))
if u not in test_items or test_items[u][-1] < time:
test_items[u] = (i, rating, time)
for u in range(1, num_users + 1):
train_list.extend(sorted(train_items[u], key=lambda k: k[3]))
test_data = [(key, *value) for key, value in test_items.items()]
train_data = [item for item in train_list if item not in test_data]
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
else:
mask = [True if x == 1 else False for x in np.random.uniform(
0, 1, (len(data))) < 1 - test_ratio]
neg_mask = [not x for x in mask]
train_data, test_data = data[mask], data[neg_mask]
return train_data, test_data
请注意,在实践中,除了测试集之外,使用验证集是一个好习惯。但是,为简洁起见,我们省略了这一点。在这种情况下,我们的测试集可以被视为我们的留出验证集。
21.2.4. 加载数据¶
数据集划分后,为了方便起见,我们将把训练集和测试集转换成列表和字典/矩阵。以下函数逐行读取数据帧,并从零开始枚举用户/项目的索引。然后,该函数返回用户、项目、评分的列表以及一个记录交互的字典/矩阵。我们可以将反馈类型指定为explicit(显式)或implicit(隐式)。
#@save
def load_data_ml100k(data, num_users, num_items, feedback='explicit'):
users, items, scores = [], [], []
inter = np.zeros((num_items, num_users)) if feedback == 'explicit' else {}
for line in data.itertuples():
user_index, item_index = int(line[1] - 1), int(line[2] - 1)
score = int(line[3]) if feedback == 'explicit' else 1
users.append(user_index)
items.append(item_index)
scores.append(score)
if feedback == 'implicit':
inter.setdefault(user_index, []).append(item_index)
else:
inter[item_index, user_index] = score
return users, items, scores, inter
之后,我们将上述步骤整合在一起,并将在下一节中使用。结果被包装在Dataset和DataLoader中。请注意,训练数据的DataLoader的last_batch设置为rollover模式(剩余的样本将滚动到下一个轮次),并且顺序被打乱。
#@save
def split_and_load_ml100k(split_mode='seq-aware', feedback='explicit',
test_ratio=0.1, batch_size=256):
data, num_users, num_items = read_data_ml100k()
train_data, test_data = split_data_ml100k(
data, num_users, num_items, split_mode, test_ratio)
train_u, train_i, train_r, _ = load_data_ml100k(
train_data, num_users, num_items, feedback)
test_u, test_i, test_r, _ = load_data_ml100k(
test_data, num_users, num_items, feedback)
train_set = gluon.data.ArrayDataset(
np.array(train_u), np.array(train_i), np.array(train_r))
test_set = gluon.data.ArrayDataset(
np.array(test_u), np.array(test_i), np.array(test_r))
train_iter = gluon.data.DataLoader(
train_set, shuffle=True, last_batch='rollover',
batch_size=batch_size)
test_iter = gluon.data.DataLoader(
test_set, batch_size=batch_size)
return num_users, num_items, train_iter, test_iter
21.2.5. 小结¶
MovieLens数据集被广泛用于推荐研究。它是公开可用且免费使用的。
我们定义了函数来下载和预处理MovieLens 100k数据集,以供后续章节使用。