11.9. Transformer的大规模预训练¶ 在 SageMaker Studio Lab 中打开 Notebook
到目前为止,在我们的图像分类和机器翻译实验中,模型都是在带有输入-输出示例的数据集上*从头开始*训练以执行特定任务的。例如,一个Transformer模型在英法对上进行训练(第 11.7 节),以便该模型可以将输入的英文文本翻译成法文。因此,每个模型都成为了一个*特定的专家*,对数据分布的轻微变化都非常敏感(第 4.7 节)。为了获得泛化能力更好的模型,甚至是能胜任多个任务的*通才*(无论是否需要适应),在大型数据上进行模型*预训练*已经变得越来越普遍。
在更大的预训练数据下,随着模型尺寸和训练计算量的增加,Transformer架构表现得更好,展示了优越的*扩展性*(scaling)。具体来说,基于Transformer的语言模型的性能随着模型参数量、训练词元数和训练计算量呈幂律关系增长(Kaplan et al., 2020)。在更大规模数据上训练的更大视觉Transformer(在第 11.8 节中讨论)性能显著提升,也证明了Transformer的可扩展性。最近的成功案例包括Gato,一个可以玩雅达利游戏、为图像配字幕、聊天和充当机器人的*通才*模型(Reed et al., 2022)。Gato是一个单一的Transformer,在包括文本、图像、关节扭矩和按钮按压等多种模态上进行预训练时,表现出良好的扩展性。值得注意的是,所有这些多模态数据都被序列化为一个扁平的词元序列,可以像处理文本词元(第 11.7 节)或图像块(第 11.8 节)一样由Transformer处理。
在预训练Transformer在多模态数据上取得引人注目的成功之前,Transformer已经在大量文本上进行了广泛的预训练。最初为机器翻译提出的Transformer架构(如图 11.7.1)包含一个用于表示输入序列的编码器和一个用于生成目标序列的解码器。主要地,Transformer可以以三种不同的模式使用:*仅编码器*、*编码器-解码器*和*仅解码器*。在本章的结尾,我们将回顾这三种模式,并解释预训练Transformer的可扩展性。
11.9.1. 仅编码器¶
当仅使用Transformer编码器时,一个输入词元序列被转换为相同数量的表示,这些表示可以进一步投影到输出(例如,分类)。Transformer编码器由自注意力层组成,其中所有输入词元都相互关注。例如,图 11.8.1中描绘的视觉Transformer是仅编码器的,将一个输入图像块序列转换为一个特殊的“<cls>”词元的表示。由于这个表示依赖于所有输入词元,它被进一步投影到分类标签上。这一设计受到了一个更早的在文本上预训练的仅编码器Transformer的启发:BERT(Bidirectional Encoder Representations from Transformers)(Devlin et al., 2018)。
11.9.1.1. 预训练BERT¶

图 11.9.1 左:使用掩码语言模型预训练BERT。对被掩码的词元“love”的预测依赖于“love”之前和之后的所有输入词元。右:Transformer编码器中的注意力模式。纵轴上的每个词元都关注横轴上的所有输入词元。¶
BERT通过*掩码语言模型*在文本序列上进行预训练:将随机掩盖了词元的输入文本送入一个Transformer编码器,以预测被掩盖的词元。如图 11.9.1所示,一个原始文本序列“I”、“love”、“this”、“red”、“car”在前面加上了“<cls>”词元,而“<mask>”词元随机替换了“love”;然后在预训练期间,需要最小化被掩码词元“love”与其预测之间的交叉熵损失。请注意,Transformer编码器的注意力模式没有限制(图 11.9.1的右侧),因此所有词元都可以相互关注。因此,“love”的预测依赖于序列中它之前和之后的输入词元。这就是为什么BERT是一个“双向编码器”。无需人工标注,来自书籍和维基百科的大规模文本数据可用于预训练BERT。
11.9.1.2. 微调BERT¶
预训练的BERT可以被*微调*以适应涉及单个文本或文本对的下游编码任务。在微调期间,可以向BERT添加具有随机化参数的附加层:这些参数和那些预训练的BERT参数将被*更新*以适应下游任务的训练数据。

图 11.9.2 为情感分析微调BERT。¶
图 11.9.2展示了为情感分析微调BERT的过程。Transformer编码器是一个预训练的BERT,它接收一个文本序列作为输入,并将“<cls>”表示(输入的全局表示)送入一个额外的全连接层来预测情感。在微调期间,通过基于梯度的算法最小化预测和情感分析数据标签之间的交叉熵损失,其中附加层从头开始训练,而BERT的预训练参数被更新。BERT能做的不仅仅是情感分析。这个拥有3.5亿参数的BERT从2500亿个训练词元中学到的通用语言表示,提升了自然语言任务的最新水平,例如单个文本分类、文本对分类或回归、文本标注和问答。
您可能注意到,这些下游任务包括文本对理解。BERT预训练还有另一个损失,用于预测一个句子是否紧跟在另一个句子之后。然而,后来发现在对一个同样大小的BERT变体RoBERTa进行2万亿词元预训练时,这个损失的作用不大(Liu et al., 2019)。BERT的其他衍生模型改进了模型架构或预训练目标,例如ALBERT(强制参数共享)(Lan et al., 2019)、SpanBERT(表示和预测文本片段)(Joshi et al., 2020)、DistilBERT(通过知识蒸馏实现轻量化)(Sanh et al., 2019)和ELECTRA(替换词元检测)(Clark et al., 2020)。此外,BERT启发了计算机视觉领域的Transformer预训练,例如视觉Transformer(Dosovitskiy et al., 2021)、Swin Transformer(Liu et al., 2021)和MAE(掩码自编码器)(He et al., 2022)。
11.9.2. 编码器-解码器¶
由于Transformer编码器将一个输入词元序列转换为相同数量的输出表示,仅编码器模式无法像在机器翻译中那样生成任意长度的序列。正如最初为机器翻译提出的那样,Transformer架构可以配备一个解码器,该解码器以自回归方式逐词元地预测任意长度的目标序列,其条件是编码器输出和解码器输出:(i)为了以编码器输出为条件,编码器-解码器交叉注意力(图 11.7.1中解码器的多头注意力)允许目标词元关注*所有*输入词元;(ii)以解码器输出为条件是通过所谓的*因果*注意力模式(这个名称在文献中很常见,但具有误导性,因为它与因果关系的适当研究几乎没有联系)(图 11.7.1中解码器的掩码多头注意力)实现的,其中任何目标词元只能关注目标序列中的*过去*和*当前*词元。
为了在人工标注的机器翻译数据之外预训练编码器-解码器Transformer,BART (Lewis et al., 2019) 和 T5 (Raffel et al., 2020) 是两个同时提出并在大规模文本语料库上预训练的编码器-解码器Transformer。两者都试图在它们的预训练目标中重建原始文本,前者强调对输入进行加噪(例如,掩码、删除、排列和旋转),而后者则通过全面的消融研究强调多任务统一。
11.9.2.1. 预训练T5¶
作为预训练的Transformer编码器-解码器的一个例子,T5(Text-to-Text Transfer Transformer)将许多任务统一为同一个文本到文本的问题:对于任何任务,编码器的输入是一个任务描述(例如,“Summarize”、“:”)后跟任务输入(例如,来自一篇文章的词元序列),而解码器预测任务输出(例如,总结输入文章的词元序列)。为了实现文本到文本的功能,T5被训练成在给定输入文本的条件下生成一些目标文本。

图 11.9.3 左:通过预测连续片段来预训练T5。原始句子是“I”、“love”、“this”、“red”、“car”,其中“love”被一个特殊的“<X>”词元替换,连续的“red”、“car”被一个特殊的“<Y>”词元替换。目标序列以一个特殊的“<Z>”词元结束。右:Transformer编码器-解码器中的注意力模式。在编码器自注意力(下方正方形)中,所有输入词元相互关注;在编码器-解码器交叉注意力(上方矩形)中,每个目标词元关注所有输入词元;在解码器自注意力(上方三角形)中,每个目标词元仅关注当前和过去的目标词元(因果)。¶
为了从任何原始文本中获取输入和输出,T5被预训练来预测连续的片段。具体来说,文本中的词元被随机替换为特殊词元,其中每个连续片段被同一个特殊词元替换。考虑图 11.9.3中的例子,原始文本是“I”、“love”、“this”、“red”、“car”。词元“love”、“red”、“car”被随机替换为特殊词元。由于“red”和“car”是一个连续片段,它们被同一个特殊词元替换。结果,输入序列是“I”、“<X>”、“this”、“<Y>”,目标序列是“<X>”、“love”、“<Y>”、“red”、“car”、“<Z>”,其中“<Z>”是另一个标记结束的特殊词元。如图 11.9.3所示,解码器具有因果注意力模式,以防止其在序列预测过程中关注未来的词元。
在T5中,预测连续片段也被称为重建损坏的文本。通过这个目标,T5在C4(Colossal Clean Crawled Corpus)数据的1万亿词元上进行了预训练,该数据由来自网络的干净英文文本组成(Raffel et al., 2020)。
11.9.2.2. 微调T5¶
与BERT类似,T5需要在特定任务的训练数据上进行微调(更新T5参数)以执行该任务。与BERT微调的主要区别包括:(i)T5的输入包含任务描述;(ii)T5可以通过其Transformer解码器生成任意长度的序列;(iii)不需要额外的层。

图 11.9.4 为文本摘要微调T5。任务描述和文章词元都送入Transformer编码器以预测摘要。¶
图 11.9.4以文本摘要为例解释了T5的微调。在这个下游任务中,任务描述词元“Summarize”、“:”后跟文章词元被输入到编码器。
经过微调后,拥有110亿参数的T5(T5-11B)在多个编码(如分类)和生成(如摘要)基准测试中取得了最先进的结果。自发布以来,T5在后续研究中被广泛使用。例如,switch Transformer是基于T5设计的,用于激活部分参数以提高计算效率(Fedus et al., 2022)。在一个名为Imagen的文本到图像模型中,文本被输入到一个拥有46亿参数的冻结T5编码器(T5-XXL)中(Saharia et al., 2022)。图 11.9.5中的照片级文本到图像示例表明,即使没有微调,T5编码器本身也可能有效地表示文本。

11.9.3. 仅解码器¶
我们已经回顾了仅编码器和编码器-解码器的Transformer。另外,仅解码器的Transformer从图 11.7.1中描绘的原始编码器-解码器架构中移除了整个编码器和带有编码器-解码器交叉注意力的解码器子层。如今,仅解码器的Transformer已成为大规模语言建模(第 9.3 节)中*事实上的*架构,它通过自监督学习利用了世界上丰富的未标注文本语料库。
11.9.3.1. GPT和GPT-2¶
GPT(生成式预训练)模型使用语言建模作为训练目标,选择Transformer解码器作为其骨干(Radford et al., 2018)。

图 11.9.6 左:使用语言建模预训练GPT。目标序列是输入序列向右移动一个词元。 “<bos>”和“<eos>”都是分别标记序列开始和结束的特殊词元。右:Transformer解码器中的注意力模式。纵轴上的每个词元仅关注其在横轴上的过去词元(因果)。¶
遵循第 9.3.3 节中描述的自回归语言模型训练,图 11.9.6展示了使用Transformer编码器进行GPT预训练,其中目标序列是输入序列向右移动一个词元。请注意,Transformer解码器中的注意力模式强制每个词元只能关注其过去的词元(未来的词元不能被关注,因为它们尚未被选择)。
GPT拥有1亿个参数,需要为各个下游任务进行微调。一年后,一个更大的Transformer解码器语言模型GPT-2被引入(Radford et al., 2019)。与GPT中的原始Transformer解码器相比,GPT-2采用了预归一化(在第 11.8.3 节中讨论)、改进的初始化和权重缩放。在40GB的文本上进行预训练,拥有15亿参数的GPT-2在语言建模基准测试中取得了最先进的结果,并在多个其他任务上取得了有希望的结果,而*无需更新参数或架构*。
11.9.3.2. GPT-3及以后¶
GPT-2展示了在不更新模型的情况下,使用同一个语言模型执行多个任务的潜力。这比需要通过梯度计算进行模型更新的微调在计算上更高效。

图 11.9.7 使用语言模型(Transformer解码器)进行零样本、一样本、少样本的上下文学习。不需要参数更新。¶
在解释不更新参数而更高效地使用语言模型之前,回顾第 9.5 节,一个语言模型可以被训练成在给定某个前缀文本序列的条件下生成一个文本序列。因此,一个预训练的语言模型可以在*不更新参数*的情况下,根据一个包含任务描述、特定任务的输入-输出示例和一个提示(任务输入)的输入序列,生成任务输出序列。这种学习范式被称为*上下文学习*(Brown et al., 2020),当没有、有一个或有几个特定任务的输入-输出示例时,可以进一步分为*零样本*、*一样本*和*少样本*(图 11.9.7)。
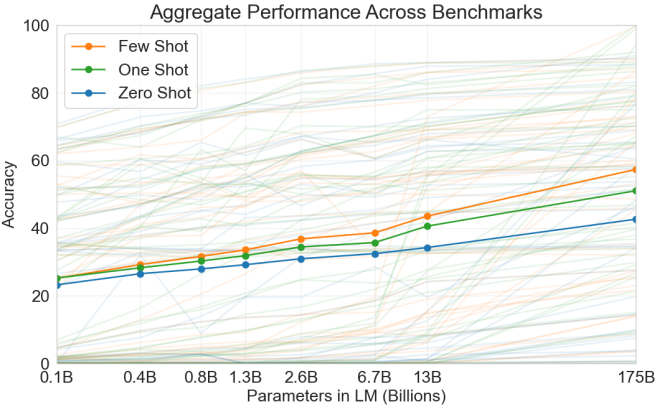
这三种设置在GPT-3中进行了测试(Brown et al., 2020),其最大版本的模型使用的数据和模型大小比GPT-2大约两个数量级。GPT-3使用与其直接前身GPT-2相同的Transformer解码器架构,不同之处在于交替层的注意力模式(在图 11.9.6的右侧)更为稀疏。在3000亿个词元上进行预训练,GPT-3随着模型尺寸的增大表现得更好,其中少样本性能增长最快(图 11.9.8)。
随后的GPT-4模型在其报告中没有完全披露技术细节(OpenAI, 2023)。与其前身相比,GPT-4是一个大规模的多模态模型,可以同时接收文本和图像作为输入,并生成文本输出。
11.9.4. 可扩展性¶
图 11.9.8凭经验证明了GPT-3语言模型中Transformer的可扩展性。对于语言建模,关于Transformer可扩展性的更全面的经验研究让研究人员看到了用更多数据和计算资源训练更大Transformer的前景(Kaplan et al., 2020)。
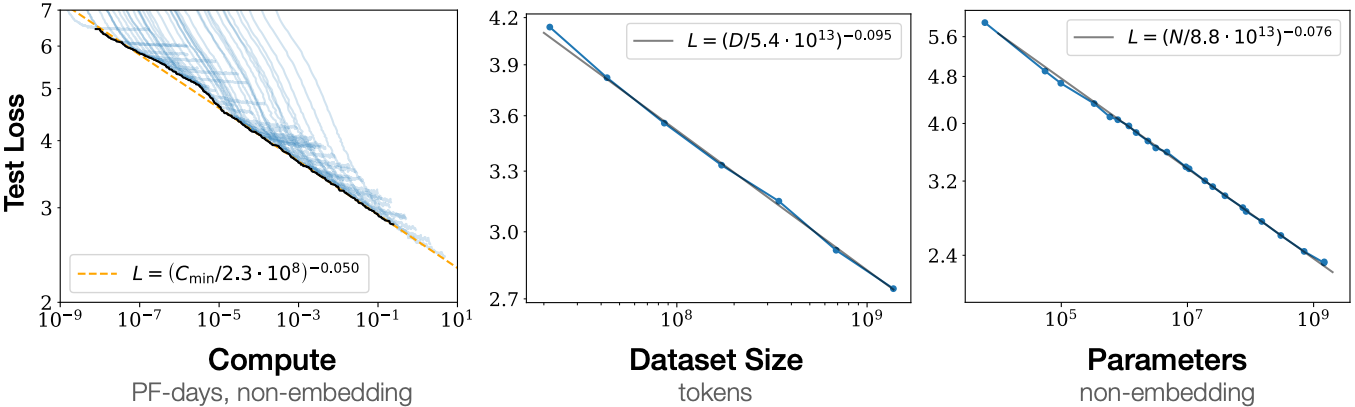
图 11.9.9 随着我们增加模型大小、数据集大小和用于训练的计算量,Transformer语言模型的性能会平滑提高。为了获得最佳性能,所有这三个因素必须同步扩大。当不受其他两个因素瓶颈限制时,经验性能与每个单独因素之间存在幂律关系(标题改编和图片取自 Kaplan et al. (2020))。¶
如图 11.9.9所示,可以观察到性能与模型大小(参数数量,不包括嵌入层)、数据集大小(训练词元数量)和训练计算量(PetaFLOP/s-天,不包括嵌入层)之间的*幂律扩展*关系。总的来说,同步增加这三个因素会导致更好的性能。然而,*如何*同步增加它们仍然是一个有争议的问题(Hoffmann et al., 2022)。
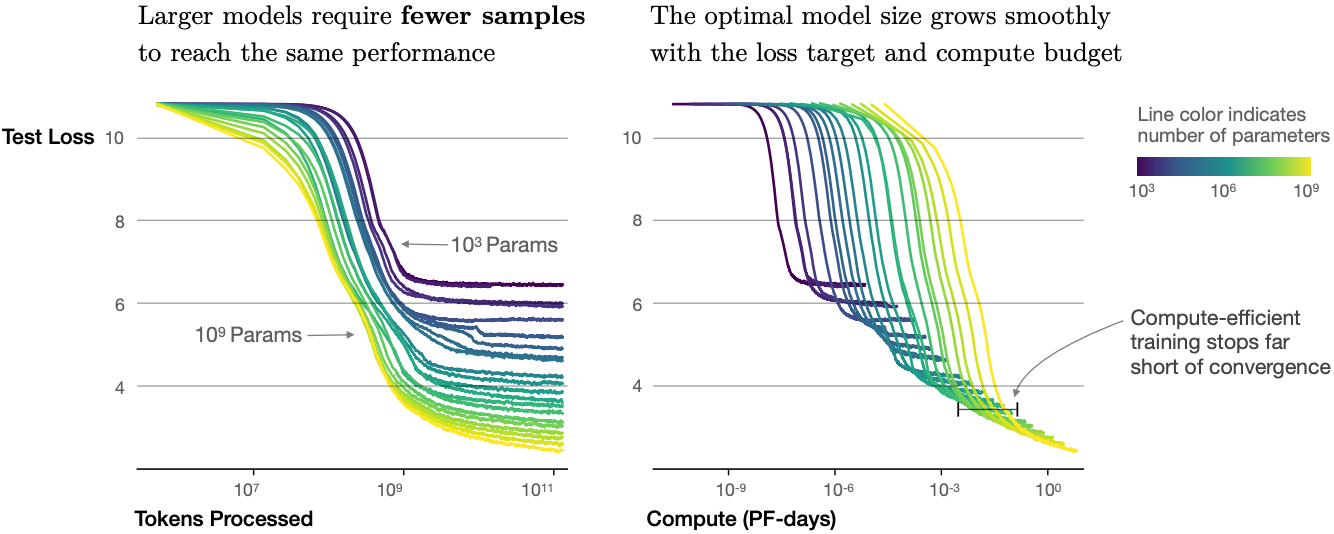
除了性能提升外,大模型还比小模型享有更好的样本效率。图 11.9.10显示,大模型需要更少的训练样本(处理的词元)来达到小模型所能达到的相同水平,并且性能随着计算量的增加而平滑扩展。
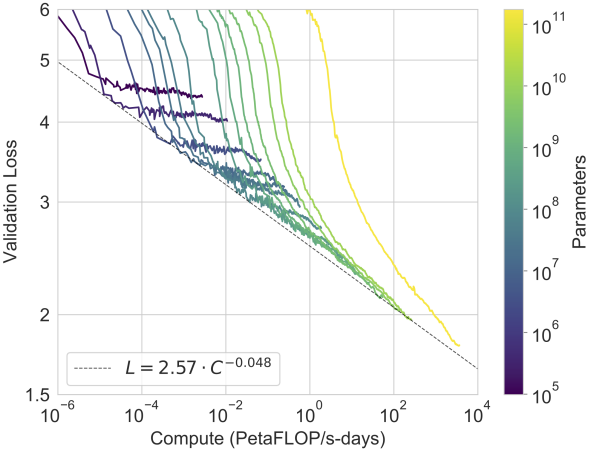
图 11.9.11 GPT-3的性能(交叉熵验证损失)与用于训练的计算量之间遵循幂律趋势。在Kaplan et al. (2020)中观察到的幂律行为在额外两个数量级上仍然持续,与预测曲线只有很小的偏差。嵌入参数不包括在计算和参数计数中(标题改编和图片取自Brown et al. (2020))。¶
Kaplan et al. (2020)中的经验扩展行为已在后续的大型Transformer模型中得到验证。例如,GPT-3在图 11.9.11中以两个数量级的增加支持了这一假设。
11.9.5. 大型语言模型¶
GPT系列中Transformer的可扩展性启发了后续的大型语言模型。GPT-2 Transformer解码器被用于训练拥有5300亿参数的Megatron-Turing NLG(Smith et al., 2022),使用了2700亿训练词元。遵循GPT-2的设计,拥有2800亿参数的Gopher(Rae et al., 2021)在3000亿词元上进行了预训练,在各种任务中表现出色。继承了Gopher相同的架构并使用相同的计算预算,Chinchilla(Hoffmann et al., 2022)是一个规模小得多(700亿参数)的模型,但训练时间更长(1.4万亿训练词元),在许多任务上超过了Gopher,并更加强调词元数量而非参数数量。为了继续语言建模的扩展路线,PaLM(Pathway Language Model)(Chowdhery et al., 2022)是一个拥有5400亿参数、经过修改设计的Transformer解码器,在7800亿词元上进行了预训练,在BIG-Bench基准测试中超过了人类平均表现(Srivastava et al., 2022)。其后续版本PaLM 2(Anil et al., 2023)的数据和模型规模大致以1:1的比例扩展,并提高了多语言和推理能力。其他大型语言模型,如Minerva(Lewkowycz et al., 2022)(进一步训练了一个通才模型PaLM)和Galactica(Taylor et al., 2022)(未在通用语料库上训练),已显示出有希望的定量和科学推理能力。
开源发布,如OPT(Open Pretrained Transformers)(Zhang et al., 2022)、BLOOM(Scao et al., 2022)和FALCON(Penedo et al., 2023),推动了大型语言模型的研究和使用的民主化。专注于推理时计算效率的开源Llama 1(Touvron et al., 2023a)通过在比通常使用更多的词元上训练,超越了规模大得多的模型。更新后的Llama 2(Touvron et al., 2023b)进一步将预训练语料库增加了40%,从而产生了可能与有竞争力的闭源模型性能相媲美的产品模型。
Wei et al. (2022) 讨论了大型语言模型的涌现能力,这些能力存在于大型模型中,但不存在于小型模型中。然而,仅仅增加模型大小并不能天然地让模型更好地遵循人类指令。Sanh et al. (2021), Wei et al. (2021) 发现,在一系列通过*指令*描述的数据集上微调大型语言模型,可以提高在未见任务上的零样本性能。使用*来自人类反馈的强化学习*,Ouyang et al. (2022) 微调了GPT-3以遵循多样化的指令集。遵循由此产生的InstructGPT,它通过微调使语言模型与人类意图对齐(Ouyang et al., 2022),ChatGPT可以根据与人类的对话生成类似人类的响应(例如,代码调试和创意写作),并且可以零样本执行许多自然语言处理任务(Qin et al., 2023)。Bai et al. (2022) 用模型输出来替代人类输入(例如,人类标注的数据),以部分自动化指令微调过程,这也被称为*来自AI反馈的强化学习*。
大型语言模型提供了一个令人兴奋的前景,即通过构造文本输入来引导模型通过上下文学习执行期望的任务,这也被称为*提示(prompting)*。值得注意的是,*思维链提示*(Wei et al., 2022)是一种上下文学习方法,它通过少样本的“问题、中间推理步骤、答案”演示,激发大型语言模型的复杂推理能力,以解决数学、常识和符号推理任务。采样多个推理路径(Wang et al., 2023)、多样化少样本演示(Zhang et al., 2023)以及将复杂问题简化为子问题(Zhou et al., 2023)都可以提高推理的准确性。事实上,通过在每个答案前加上简单的提示,如“让我们一步一步地思考”,大型语言模型甚至可以以相当高的准确性执行*零样本*思维链推理(Kojima et al., 2022)。即使对于包含文本和图像的多模态输入,语言模型也可以执行多模态思维链推理,其准确性高于仅使用文本输入(Zhang et al., 2023)。
11.9.6. 总结与讨论¶
Transformer已被预训练为仅编码器(例如,BERT)、编码器-解码器(例如,T5)和仅解码器(例如,GPT系列)模型。预训练模型可以通过模型更新(例如,微调)或不更新(例如,少样本)来适应执行不同的任务。Transformer的可扩展性表明,更大的模型、更多的训练数据和更多的训练计算量会带来更好的性能。由于Transformer最初是为文本数据设计和预训练的,本节略微偏向于自然语言处理。尽管如此,上面讨论的那些模型通常可以在跨多个模态的最新模型中找到。例如,(i) Chinchilla (Hoffmann et al., 2022) 被进一步扩展为Flamingo (Alayrac et al., 2022),一个用于少样本学习的视觉语言模型;(ii) GPT-2 (Radford et al., 2019) 和视觉Transformer在CLIP(对比语言-图像预训练)中对文本和图像进行编码(Radford et al., 2021),其图像和文本嵌入后来被DALL-E 2文本到图像系统采用(Ramesh et al., 2022)。虽然目前还没有关于Transformer在多模态预训练中可扩展性的系统研究,但一个名为Parti的全Transformer文本到图像模型(Yu et al., 2022)显示了跨模态可扩展的潜力:一个更大的Parti在生成高保真图像和理解内容丰富的文本方面能力更强(图 11.9.12)。
