13.2. 异步计算¶ 在 SageMaker Studio Lab 中打开 Notebook
如今的计算机是高度并行的系统,由多个CPU核(通常每个核有多个线程)、GPU上的多个处理单元、以及单个设备上的多个GPU组成。简而言之,我们可以在同一时间处理许多不同的事情,而且通常是在不同的设备上。不幸的是,Python并不是编写并行和异步代码的好工具,至少在没有额外帮助的情况下是这样。毕竟,Python是单线程的,而且在可预见的未来这一点也不太可能改变。MXNet和TensorFlow等深度学习框架采用*异步编程*模型来提高性能,而PyTorch则使用Python自己的调度器,这导致了不同的性能权衡。对于PyTorch,GPU操作默认是异步的。当你调用一个使用GPU的函数时,这些操作会被放入特定设备的队列中,但不一定立即执行。这使得我们能够并行执行更多的计算,包括在CPU或其他GPU上的操作。
因此,了解异步编程的工作原理有助于我们开发更高效的程序,通过主动减少计算需求和相互依赖。这使我们能够减少内存开销并提高处理器利用率。
import os
import subprocess
import numpy
import torch
from torch import nn
from d2l import torch as d2l
import os
import subprocess
import numpy
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()
13.2.1. 通过后端实现异步¶
为了热身,我们先来看一个简单的问题:我们想要生成一个随机矩阵并将其相乘。让我们在NumPy和PyTorch张量中都这样做,看看有什么区别。请注意,PyTorch的 tensor 是在GPU上定义的。
# Warmup for GPU computation
device = d2l.try_gpu()
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('torch'):
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
numpy: 1.4693 sec
torch: 0.0022 sec
PyTorch的基准测试输出要快几个数量级。NumPy的点积在CPU处理器上执行,而PyTorch的矩阵乘法在GPU上执行,因此后者预计会快得多。但巨大的时间差表明肯定还有其他原因。默认情况下,GPU操作在PyTorch中是异步的。强制PyTorch在返回之前完成所有计算,揭示了之前发生的事情:计算是由后端执行的,而前端将控制权交还给了Python。
with d2l.Benchmark():
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
torch.cuda.synchronize(device)
Done: 0.0058 sec
广义上说,PyTorch有一个用于与用户直接交互的前端(例如,通过Python),以及一个供系统执行计算的后端。如 图 13.2.1 所示,用户可以用各种前端语言编写PyTorch程序,如Python和C++。无论使用何种前端编程语言,PyTorch程序的执行主要发生在C++实现的后端。由前端语言发出的操作被传递到后端执行。后端管理着自己的线程,这些线程不断地收集和执行排队的任务。请注意,为了让这一切正常工作,后端必须能够跟踪计算图中各个步骤之间的依赖关系。因此,不可能并行化相互依赖的操作。
为了热身,我们先来看一个简单的问题:我们想要生成一个随机矩阵并将其相乘。让我们在NumPy和 mxnet.np 中都这样做,看看有什么区别。
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('mxnet.np'):
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
numpy: 0.8850 sec
mxnet.np: 0.0164 sec
[21:49:14] ../src/storage/storage.cc:196: Using Pooled (Naive) StorageManager for CPU
MXNet的基准测试输出要快几个数量级。由于两者都在同一个处理器上执行,肯定还有其他原因。强制MXNet在返回之前完成所有后端计算,揭示了之前发生的事情:计算是由后端执行的,而前端将控制权交还给了Python。
with d2l.Benchmark():
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
npx.waitall()
Done: 1.4073 sec
广义上说,MXNet有一个用于与用户直接交互的前端(例如,通过Python),以及一个供系统执行计算的后端。如 图 13.2.1 所示,用户可以用各种前端语言编写MXNet程序,如Python、R、Scala和C++。无论使用何种前端编程语言,MXNet程序的执行主要发生在C++实现的后端。由前端语言发出的操作被传递到后端执行。后端管理着自己的线程,这些线程不断地收集和执行排队的任务。请注意,为了让这一切正常工作,后端必须能够跟踪计算图中各个步骤之间的依赖关系。因此,不可能并行化相互依赖的操作。
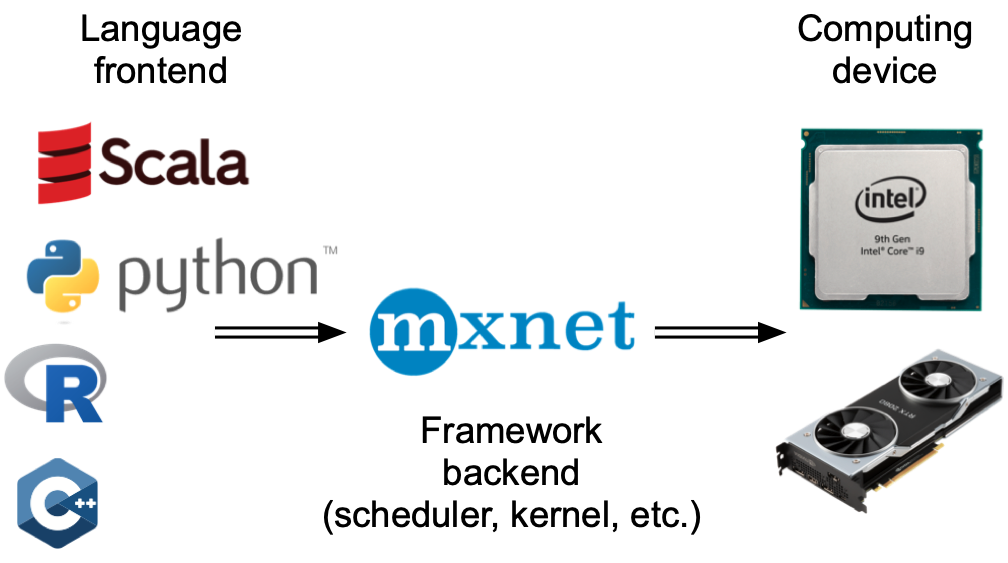
图 13.2.1 编程语言前端和深度学习框架后端。¶
让我们看另一个简单的例子,以便更好地理解依赖图。
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
z
tensor([[3., 3.]], device='cuda:0')
x = np.ones((1, 2))
y = np.ones((1, 2))
z = x * y + 2
z
array([[3., 3.]])

图 13.2.2 后端跟踪计算图中各个步骤之间的依赖关系。¶
上面的代码片段也在 图 13.2.2 中得到了说明。每当Python前端线程执行前三个语句中的任何一个时,它只是将任务返回到后端队列。当需要*打印*最后一个语句的结果时,Python前端线程将等待C++后端线程完成计算变量 z 的结果。这种设计的一个好处是Python前端线程不需要执行实际计算。因此,无论Python的性能如何,对程序的整体性能影响很小。图 13.2.3 说明了前端和后端如何交互。

图 13.2.3 前端和后端的交互。¶
13.2.2. 屏障和阻塞器¶
有许多操作会强制Python等待完成。
最明显的是
npx.waitall(),它会等待所有计算完成,无论计算指令何时发出。在实践中,除非绝对必要,否则使用此操作不是一个好主意,因为它可能导致性能不佳。如果我们只想等到某个特定变量可用,我们可以调用
z.wait_to_read()。在这种情况下,MXNet会阻塞返回Python,直到变量z被计算出来。其他计算可能在此之后继续进行。
让我们看看这在实践中是如何工作的。
with d2l.Benchmark('waitall'):
b = np.dot(a, a)
npx.waitall()
with d2l.Benchmark('wait_to_read'):
b = np.dot(a, a)
b.wait_to_read()
waitall: 0.0180 sec
wait_to_read: 0.0189 sec
两个操作完成所需的时间大致相同。除了明显的阻塞操作外,我们建议您注意*隐式*阻塞器。打印一个变量显然需要该变量可用,因此它是一个阻塞器。最后,通过 z.asnumpy() 转换为NumPy和通过 z.item() 转换为标量都是阻塞的,因为NumPy没有异步的概念。它需要访问这些值,就像 print 函数一样。
频繁地从MXNet的范围向NumPy复制少量数据(反之亦然)可能会破坏一个原本高效的代码的性能,因为每个这样的操作都要求计算图在做任何其他事情*之前*,先评估获得相关项所需的所有中间结果。
with d2l.Benchmark('numpy conversion'):
b = np.dot(a, a)
b.asnumpy()
with d2l.Benchmark('scalar conversion'):
b = np.dot(a, a)
b.sum().item()
numpy conversion: 0.0340 sec
scalar conversion: 0.0445 sec
13.2.3. 改进计算¶
在一个高度多线程的系统上(即使是普通的笔记本电脑也有4个或更多的线程,在多插槽服务器上这个数字可能超过256),调度操作的开销可能会变得很大。这就是为什么让计算和调度异步并行进行是非常可取的。为了说明这样做的好处,让我们看看如果我们将一个变量多次加1,分别以顺序和异步方式进行会发生什么。我们通过在每次加法之间插入一个 wait_to_read 屏障来模拟同步执行。
with d2l.Benchmark('synchronous'):
for _ in range(10000):
y = x + 1
y.wait_to_read()
with d2l.Benchmark('asynchronous'):
for _ in range(10000):
y = x + 1
npx.waitall()
synchronous: 3.1623 sec
asynchronous: 0.9288 sec
Python前端线程和C++后端线程之间一个稍微简化的交互可以概括如下:1. 前端命令后端将计算任务 y = x + 1 插入队列。1. 后端从队列中接收计算任务并执行实际计算。1. 后端将计算结果返回给前端。假设这三个阶段的持续时间分别为 \(t_1, t_2\) 和 \(t_3\)。如果我们不使用异步编程,执行10000次计算的总时间大约是 \(10000 (t_1+ t_2 + t_3)\)。如果使用异步编程,执行10000次计算的总时间可以减少到 \(t_1 + 10000 t_2 + t_3\) (假设 \(10000 t_2 > 9999t_1\)),因为前端不必等待后端为每个循环返回计算结果。
13.2.4. 小结¶
深度学习框架可以将Python前端与执行后端解耦。这允许快速异步地将命令插入后端并实现相关的并行性。
异步性带来了一个相当响应迅速的前端。但是,请注意不要过度填充任务队列,因为它可能导致过多的内存消耗。建议为每个小批量进行同步,以保持前端和后端大致同步。
芯片供应商提供复杂的性能分析工具,以获得对深度学习效率更细粒度的洞察。
请注意,从MXNet的内存管理转换到Python会强制后端等待,直到特定变量准备就绪。
print、asnumpy和item等函数都有这种效果。这可能是可取的,但粗心地使用同步会破坏性能。